When a table is dynamically segmented based on a measure, is there a way to retain that filtered subset to use with other measures?
Here's my scenario: I have a list of counties and using dynamic segmentation I created a measure that only returns a value if the county has JobOpenings:Unemployed ratio in the top 1% of all counties.
Selected Measure, Filtered by Pctile =
VAR
LocationsThatMeetCriteria =
FILTER (
VALUES(DimCounties[CountyID])
,COUNTROWS (
FILTER (
'Percentile Ranges',
[OpeningsToUnemployedPctile] > .99
&& [OpeningsToUnemployedPctile] <= 1
)
) > 0
)
RETURN
CALCULATE (
[OpeningsToUnemployed]
,LocationsThatMeetCriteria
)
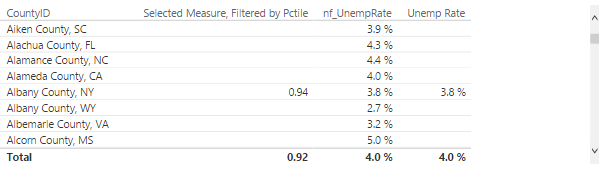
In the data table screenshot, you can see all counties in the first column. The second column shows a value if the county is in the top 1%. I wanted to create and display additional data points about the qualifying counties so I started by adding nf_UnempRate (see screenshot). The problem is that the measure doesn't consider the dynamic segmentation and returns values for all counties.
nf_UnempRate =
DIVIDE(
SUM('FactJobData'[Unemployed])
,SUM('FactJobData'[Civilian Labor Force])
,BLANK()
)
To solve that issue, I created UnempRate (see screenshot) which checks if "Selected Measure, Filtered by Pctile" is blank. If so, it returns blank too.
Unemp Rate =
IF(
[LocationFilteredOut]
,BLANK()
,[nf_UnempRate]
)
LocationFilteredOut = ISBLANK([Selected Measure, Filtered by Pctile])
This works great and when I remove "nf_UnempRate" my entire data table visual is properly filtered based on the parameter I pass for percentile. However when I add 6-7 similar columns, the performance slows to a crawl. Query Analyser shows 10,000+ steps in the logical query plan. It seems that each measure recalculates "Selected Measure, Filtered by Pctile" instead of re-using the results from the first time it was calculated.I thought that implementing Variables would solve this issue, but I can't reference a variable from another measure.
I'd like the filtered list of counties that are calculated from the first measure to be passed as the basis for calculating the other measures instead of having the system recalc that list of counties over and over again. Is there a way that you know of to accomplish this?
It seems that this feature request would solve my issue (https://ideas.powerbi.com/forums/265200-power-bi-ideas/suggestions/14950908-add-global-variables-to-... sadly is has few votes :(.
Thanks in advance!