- Power BI forums
- Updates
- News & Announcements
- Get Help with Power BI
- Desktop
- Service
- Report Server
- Power Query
- Mobile Apps
- Developer
- DAX Commands and Tips
- Custom Visuals Development Discussion
- Health and Life Sciences
- Power BI Spanish forums
- Translated Spanish Desktop
- Power Platform Integration - Better Together!
- Power Platform Integrations (Read-only)
- Power Platform and Dynamics 365 Integrations (Read-only)
- Training and Consulting
- Instructor Led Training
- Dashboard in a Day for Women, by Women
- Galleries
- Community Connections & How-To Videos
- COVID-19 Data Stories Gallery
- Themes Gallery
- Data Stories Gallery
- R Script Showcase
- Webinars and Video Gallery
- Quick Measures Gallery
- 2021 MSBizAppsSummit Gallery
- 2020 MSBizAppsSummit Gallery
- 2019 MSBizAppsSummit Gallery
- Events
- Ideas
- Custom Visuals Ideas
- Issues
- Issues
- Events
- Upcoming Events
- Community Blog
- Power BI Community Blog
- Custom Visuals Community Blog
- Community Support
- Community Accounts & Registration
- Using the Community
- Community Feedback
Register now to learn Fabric in free live sessions led by the best Microsoft experts. From Apr 16 to May 9, in English and Spanish.
- Power BI forums
- Galleries
- Quick Measures Gallery
- Re: Mean Time Between Failure (MTBF)




- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
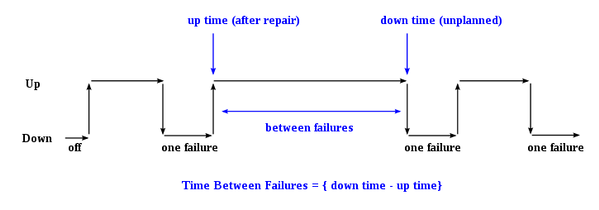
Mean Time Between Failure (MTBF)
This Quick Measure is an update to my Mean Time Between Failure (MTBF) measure that I developed in this article:
The original method had some significant column-based elements and my goal was to make this measure truly dynamic. A significant issue with the original approach is that when slicing by "Cause", the MTBF figure calculated was not truly dynamic by Cause of failure. In other words, the Uptime calculation did not account for only looking at particular causes, only between failures of the same machine. So, uptime calculated by considering all causes is vastly different than when only looking at a particular cause.
This measure corrects that flaw, although I have also included a version of the measure that does not need a calculated column but calculates uptime in the exact same way as in the aforementioned article. The new measures are down in the bottom, right-hand corner. You will notice that the new fully dynamic measure is much larger when selecting a Cause. This is because the MTBF calculation is only considering the MTBF for that particular cause.
MTBF (Hours) Measure =
VAR __table = 'Repairs'
VAR __table1 =
ADDCOLUMNS(__table,"__next",
MINX(
FILTER(__table,
[MachineName]=EARLIER([MachineName]) &&
[RepairStarted]>EARLIER([RepairStarted]) &&
[RepairType]<>"PM"
),
[RepairStarted]
)
)
VAR __table2 = ADDCOLUMNS(__table1,"__uptime",
IF([RepairType]="PM",
0,
IF(ISBLANK([__next]),
DATEDIFF([RepairCompleted],NOW(),SECOND),
DATEDIFF([RepairCompleted],[__next],SECOND)
)
)
)
VAR __repairs = CALCULATE(COUNTROWS('Repairs'),FILTER(ALLSELECTED('Repairs'),[RepairType]<>"PM"))
RETURN
DIVIDE(SUMX(__table2,[__uptime]),__repairs,BLANK())/3600
eyJrIjoiZmFjYTQwYjMtMGJlOS00Mjk4LTlkM2QtNmQ2NTc4MmU4YjAwIiwidCI6IjRhMDQyNzQzLTM3M2EtNDNkMi04MjdiLTAwM2Y0YzdiYTFlNSIsImMiOjN9
@ me in replies or I'll lose your thread!!!
Instead of a Kudo, please vote for this idea
Become an expert!: Enterprise DNA
External Tools: MSHGQM
YouTube Channel!: Microsoft Hates Greg
Latest book!: The Definitive Guide to Power Query (M)
DAX is easy, CALCULATE makes DAX hard...
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is really handy and would like to implement it in my model, however my data model is structured abit differently. I have a fact table (Notificatons) with notification data (notification, location id, breakdown status) and this is connected to a dimension table via "notificaiton" field showing the start and end times of the notifcation (lets call it MTBF table).
The fact table is connected to another dim table (location data) via location id and this contains the machine field. I am not sure how to determine the next_repair with this current model, any help will be much appreciated
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @Greg_Deckler,
Thanks for the awesome post.
However, with the previous calculated column for uptime, MTBF measure can be filter by period. Let's say for example, I don't want machine7 MTBF for the whole period, I just want machine7 MTBF for a particular peiord only. How can I tweak your codes to suit my needs?
Also, is it possible to get separate measure for just Uptime, which is the same as Uptime calculated column?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Should be possible, would need more information. Definitely been through a lot of edits with this one, the best version is in my book which fixed a bunch of bugs and other little things that I found annoying. I can reference that version but I believe some of the fixes were related to being able to properly slice the metric by things like date ranges, etc.
@ me in replies or I'll lose your thread!!!
Instead of a Kudo, please vote for this idea
Become an expert!: Enterprise DNA
External Tools: MSHGQM
YouTube Channel!: Microsoft Hates Greg
Latest book!: The Definitive Guide to Power Query (M)
DAX is easy, CALCULATE makes DAX hard...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the reply. Please find the sample attached.
You are right,
- MTBF measure is dynamic (react to particular causes) but not to date ranges.
- The original MTBF is based on calculated column of uptime, not dynamic (doesn't react to particular causes) but respond to date ranges.
- I am assuming MTBF measure1 is similar to original one? It responds to date ranges but I don't get the same value as original MTBF.
I think my issue could be solved if I can create a separate uptime measure (the one I created is not right?).
Another separate issue in my data is eliminating multiple alarms. My data source is the daily csv logs which contain thousands of events. Some sites' event duration last more than a day (>24hr) but they are captured as separate entry in the next-day csv logs. I kind of manage to eliminate those events (via Critical Alarm v2) but I am not sure that is fail safe outside of this sample data.
There are also dummy events (downtime 0hr) which I'd like to eliminate as well. Eliminating them would reduce the total critical alarm, which is vital in calculating correct mtbf and availability.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Im struggling with some points:
- What about visualizing the MTBF during days, weeks or months? I mean, to check out if the value is correct, I would like to filter it by day, check the calculations by hand and then comparing it with the measure, but the values are very wierd. How could w solve that? What about a visual showing how the MTBF is developing?
I really need this and your post is the only one I found that gets closer to my issue.
Thanks,